ServiceNow IT Operations Management (ITOM) is uniquely powerful when Event Correlation Monitoring and ITOA are seamlessly integrated.
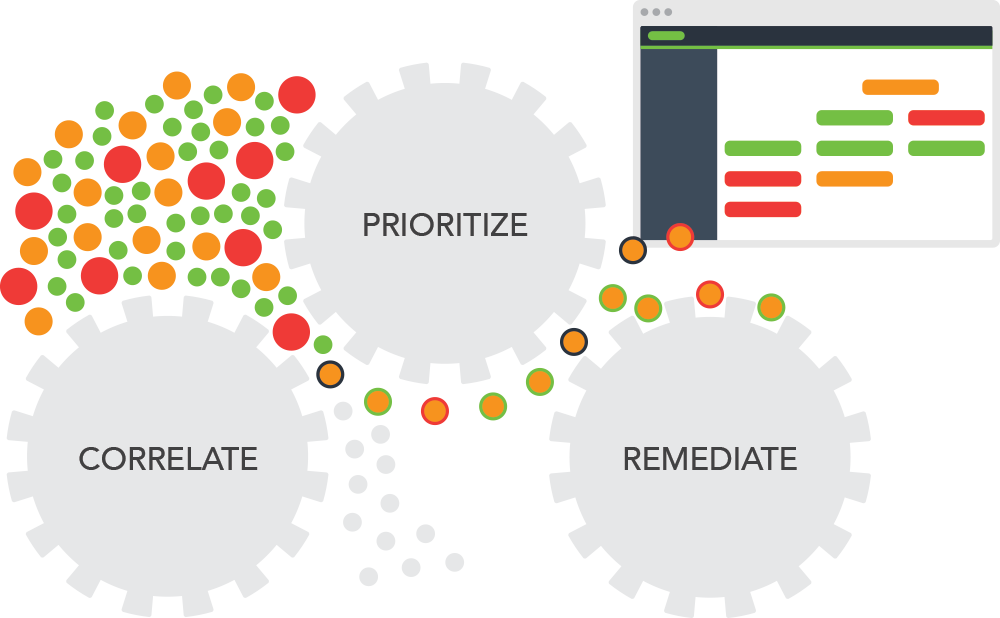
Evanios will eliminate unnecessary alerts, low-level manual decision making and back-and-forth communication between disparate groups. Because Evanios is built natively on the IT Service Management (ITSM) platform, it can extend your capabilities far beyond event and incident management.
But it’s important to recognize that the first step toward automation and advanced, actionable analytics is actually the initial data ingestion.
Many enterprise organizations are looking toward ServiceNow ITOM for features like predictive analytics – and with good cause; this kind of AI-driven functionality can help identify leading indicators and prevent outages before they occur. However, initial data ingestion plays a critical role in the usefulness of upstream analytics.
Said simply, you need to “clean up” and standardize your integrations in order to truly leverage higher end processes. Even more to the point would be the expression “Garbage in, garbage out.”
To eliminate the scenario where you throw false positives and/or miss critical information, Evanios’ ServiceNow ITOM software offers dozens of pre-packed and supported integrations. Additionally, our open API supports CMD line, TCP/UDP, REST, SNMP, log file and web service. Further, Evanios uses a standardized Common Event Format to ensure that similar alerts can be related to each other, deduplicated and correlated with high accuracy. Importantly, Evanios also maintains all original source event data directly within the ServiceNow platform. Through a combination of pre-packaged rules and extensible machine learning algorithms, our event processing engine automates root cause analysis. Comprehensive data is presented right within the event (or ServiceNow Incident) ITOM ServiceNow console – where your operators are doing their work.
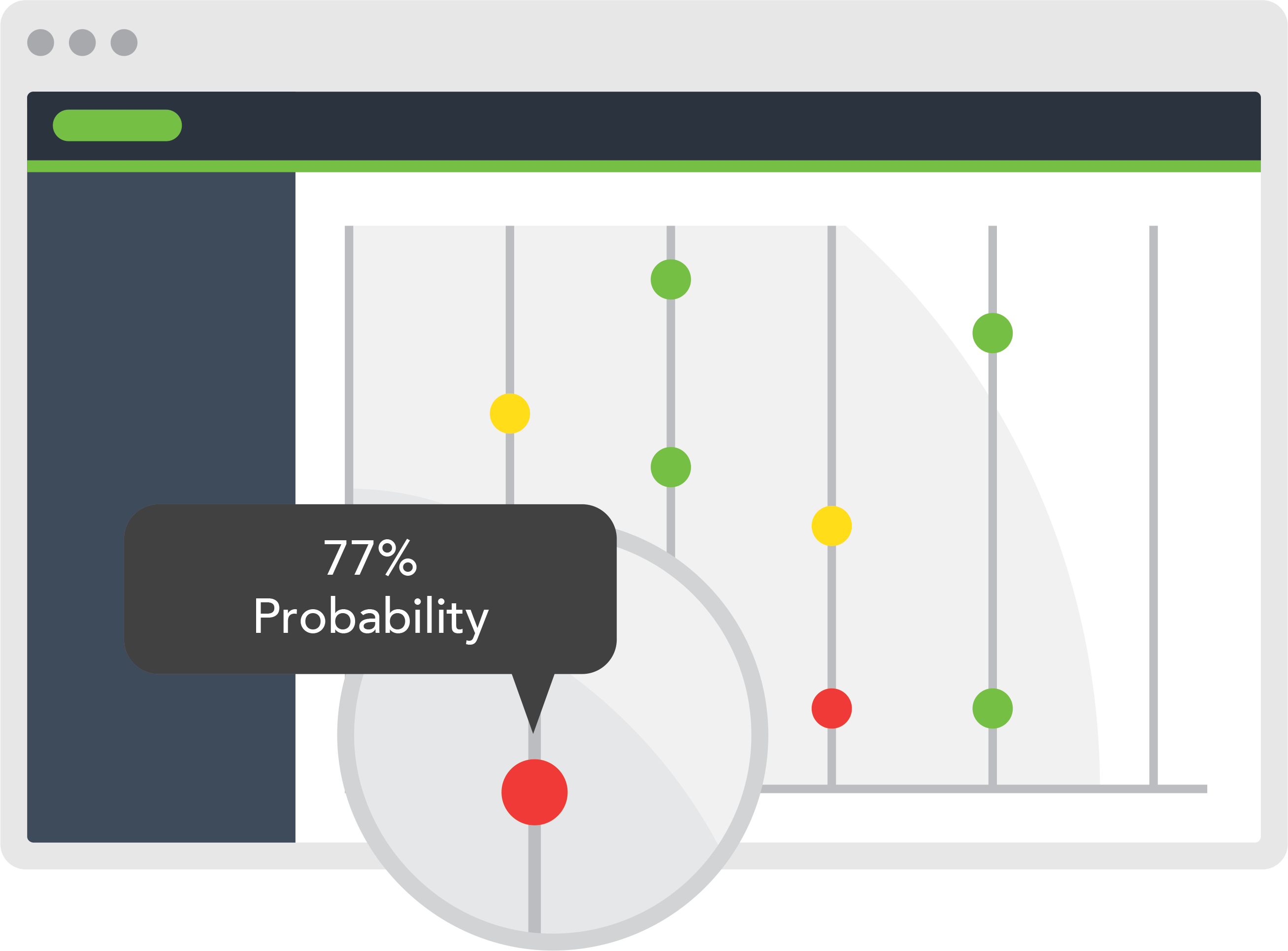
Plus, Evanios is transparent. We don’t use “black box” technology that leaves operators wondering whether they can and should trust the system’s recommendations. Instead, you’ll see a cumulative numerical score associated with every event and incident, and you can easily drill down to see where the scoring comes from. It’s a combination of context analysis (which includes CI attachments, affected business services, etc.) and predictive forecast derived from similar historical data.